Project Timeline
From concept to deployment
transforming healthcare delivery
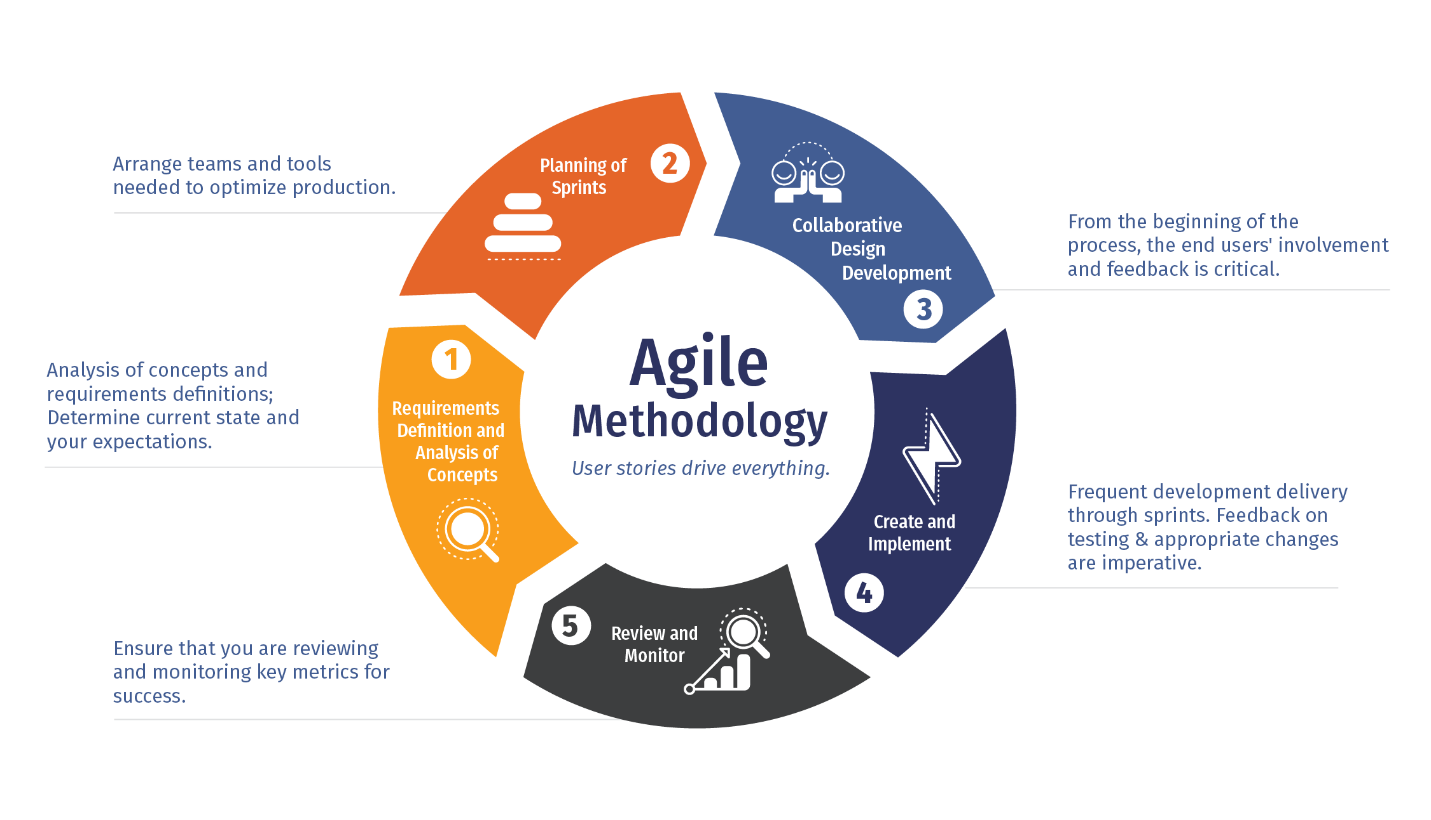
33 weeks. Five phases. 200+ clinics transformed.
Mapped 200+ clinics, identified 15 legacy systems, and defined the vision for unified healthcare monitoring.
Designed event-driven microservices architecture. Built custom adapters for legacy systems and unified GraphQL API layer.
Migrated 10+ years of patient records and 5M+ documents. Built real-time monitoring dashboard and AI-powered alert system.
Comprehensive testing across all 200+ clinics. Load testing with 10x traffic, security audits, and HIPAA compliance validation.
Phased deployment starting with 5 pilot clinics, expanding to 50, then full rollout. Real-time monitoring tracked every metric. Zero downtime achieved.